本文共 923 字,大约阅读时间需要 3 分钟。
前言
- 组件化是 保持整个 App 可持续地进行高质量开发的基础,近年来也是业界一直在积极探索和实践的方向,在深入理解组件化架构的过程中,将不断考验你的技术深度与广度;
- 实践中我还参考了十几家技术团队的解决方案(例如:美团、有赞、阿里等等),在这个系列里,我将总结我对于组件化的思考和实践。
1、知道它是什么、有什么用
相信很多人在学习的时候,一开始都会在网上找一整套资料或者买一本书来学习,结果就是内容太多,学了记不住或者学到一半感觉很难,便放弃了,更别提写代码了,根本无从入手。
而更好的一种办法便是学之前先不要着急买书,买资料,先了解一下这门语言或知识有什么作用,为什么会有这个,学习后可以解决什么问题,可以从事哪些工作,以及它的发展史,这样就可以保证我们学到的是最新的知识,以及对以后的工作方向有个大致认识。
有了这个大致的认识之后,再决定自己是否需要学习这门知识。
2、构建知识的思维导图
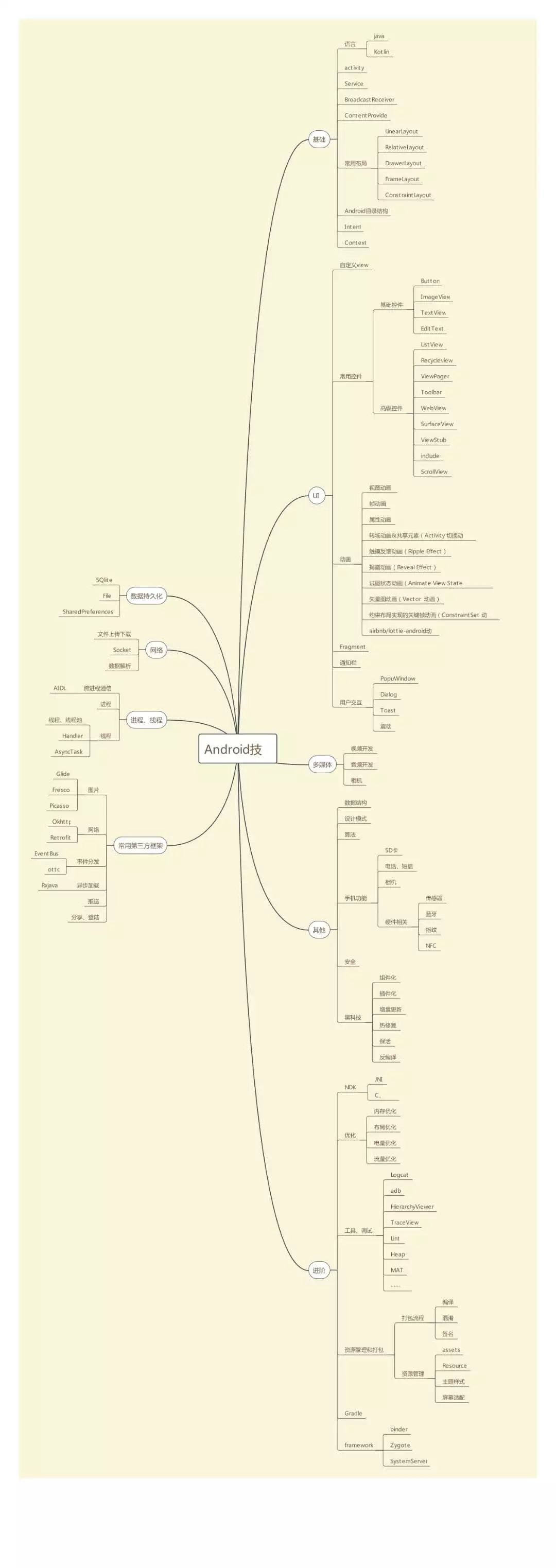
如果决定学习这门知识的话,在来构建这门知识的思维导图,它可以清楚的展现一门语言的知识结构,我们可以对照这思维导图上的知识点一个个的针对性的学习。
至于思维导图的制作可以参考书本目录和一些培训网站,尽可能的涵盖这门知识的所有知识点。
以下是我整理的 Android 方面的思维导图:
3、如何获取资料
首先你要知道你要学习的这门语言的大牛都有哪些,从大牛开始,翻找他写的书,博客、公众号寻找你需要的,所谓名师出高徒,你要知道有时候你学不会并不是你的问题!
其次寻找这门知识相关的官网和优秀社区,勤逛官网和社区可以让你大涨功力。
结尾
好了,今天的分享就到这里,如果你对在面试中遇到的问题,或者刚毕业及工作几年迷茫不知道该如何准备面试并突破现状提升自己,对于自己的未来还不够了解不知道给如何规划,可以来看看同行们都是如何突破现状,怎么学习的,来吸收他们的面试以及工作经验完善自己的之后的面试计划及职业规划。
这里放上一部分我工作以来以及参与过的大大小小的面试收集总结出来的一套****,在这里给大家,主要还是希望大家在如今大环境不好的情况下面试能够顺利一点,希望可以帮助到大家~

链图片转存中…(img-9iiENV3W-1615366614808)]

转载地址:http://hnzdz.baihongyu.com/